
[Architecture] layered architecture? clean architecture?
🔗 들어가며: 우리 프로젝트에서는 어떤 architecture를 적용해야 하는 걸까?
새로운 프로젝트를 진행하며 해당 프로젝트에서는 어떤 아키텍처를 적용하는 것이 좋을까 고민하게 되었다.
단순히 clean architecture가 유명하다는 이유로 우리 프로젝트에 도입하기보다는 우리 팀에게 어울리는 아키텍처를 선택해 적용해야겠다는 생각이 들었다.
그전에 우선 구글 권장 아키텍처인 layered architecture에 대해 학습할 필요가 있었다.
이번 게시글에서는 구글 권장 아키텍처인 전통적인 layered architecure와 clean architure의 차이점이 무엇인지, 각 아키텍처에서의 핵심은 무엇인지를 정리해보고자 한다!
🔗 clean architecture
클린 아키텍처에 대해서는 이전에 한 번 정리해둔 내용이 있다. 따라서 이번 게시글에서는 layered architecture에 대해 깊게 다뤄보고, 클린 아키텍처와의 차이점을 정리해보고자 한다!
🔗 layered architecture
사실 필자가 처음 찾아본 것은 구글 권장 아키텍처였다. 하지만 구글 권장 아키텍처가 곧 layered architecture이기 때문에 해당 부분의 내용은 layered architecture에 대한 내용이다!
우선 아키텍처 가이드 공식 페이지에 들어가게 된다면 mobile app user experience에 대한 내용이 가장 먼저 보이게 된다. 해당 부분을 읽게 된다면 왜 app component간의 의존성을 잘 구성해야 하는지에 대해 이해할 수 있다.
🔗 왜 아키텍처를 적용해야 할까?
모바일 디바이스는 제한된 리소스를 가지고 있다. 따라서 앱 프로세스는 메모리 공간 확보를 위해서는 os에 의해 언제든 소멸될 수 있기 때문에 우리의 앱 서비스는 우리가 예상한 순서에 맞지 않게 독립적으로 launch될 수 있으며, 유저에 의해 파괴될 수 있다는 것을 고려해야 한다.
이러한 상황을 생각한다면 app component 속 state와 data는 무조건적으로 저장 혹은 유지가 될 수 없기 때문에 app component들은 최소한으로 서로 depend되어야 한다.
하지만 app component에 application의 data와 state를 저장하지 못한다면 어떻게 app 자체를 구성할 수 있을까? 간단하게 우리가 텍스트 입력을 받는 ui를 구성한다고 생각해보자. 이를 위해서는 사용자 입력을 잘 가지고 있다가 필요로 하는 곳에 해당 데이터를 넘겨주어야 한다. 이처럼 application의 데이터나 state를 저장하지 못한다면 앱이 제대로 작동할 수가 없다.
앱 아키텍처는 각 레이어의 책임과 경계를 정의하는 역할을 한다. 이를 통해 변경에 유연한 구조를 구성할 수 있으며, 각각을 별도로 test할 수 있게 된다.
🔗 layered architecture principles
layered architecture에서 요구하는 원칙들을 살펴보자!
1️⃣ Separation of concerns
아마 안드로이드를 처음 개발한다면 대부분의 코드를 activity나 fragment에 몽땅 집어 넣는 경우가 있다. 이렇게 했을 때 발생할 수 있는 문제점은 모든 코드가 activity, fragment lifecycle에 연관이 되기 때문에 예상치 못한 문제가 발생할 수 있다. 또한, 그 속에 있는 별도의 코드들을 각각 테스트하기도 어렵다.
activity, fragment 구현을 own하지 말라고 공식 문서에서는 말한다. 해당 문구를 보았을 때 내가 이해했던 것은 결국에는 하나의 application에 의존하도록 코드를 구성하지 말자였다.
안드로이드 개발을 하게 되면 필수적으로 activity or fragment(compose를 사용하지 않는다면)를 구현해야 한다. 하지만 ui 혹은 application 레이어 코드가 아닌 네트워크 통신, 비즈니스 로직 등은 안드로이드 개발이 아닌 IOS 개발 등 다른 application 개발에서도 동일하게 적용될 수 있는 부분이다. 그렇기 때문에 안드로이드 application에 의존하도록 코드를 구성하지 않는다면 다양한 application 개발 환경에서 재상용할 수 있는 코드가 늘어나게 된다.
이 말은 결국, 관심사를 분리하자는 말과도 동일히다. (application 레이어의 코드와 data 레이어, domain 레이어 등의 역할과 책임을 명확히 분리하자!)
2️⃣ Drive UI from data models
ui는 data model들로부터 drive된다. 여기서 말하는 핵심은 data models들은 UI element들과 앱의 다른 component lifecycle로 부터 독립적으로 존재한다는 것이다.
또한, 가능한 persistent models로 구성하는 것이 권장된다. 이는 결국 다음 두 가지 특징을 가지게 된다.
- android os가 소멸되더라도 유저는 data를 잃지 않는다.
- 네트워크 상태와 상관없이 data model의 데이터는 값을 계속 가지고 있다.
3️⃣ Sinlge source of truth
data type을 정의한다면, SSOT를 지켜야 한다. 즉, data는 하나의 owner에 의해서만 수정이 일어난다.
이를 위해서는 ssot에서는 immutable 타입을 활용해 데이터를 노출하고, functions을 제공하여 외부로부터 이벤트를 받아 데이터를 수정하게 된다.
4️⃣ Unidirectional data flow
SSOT를 적용하게 되면 UDF 역시 자연스럽게 적용되어야 한다. SSOT에서는 하나의 source에서 데이터가 수정되며, 외부로부터 이벤트를 받는다고 했다. 이는 결국, UDF를 의미한다.
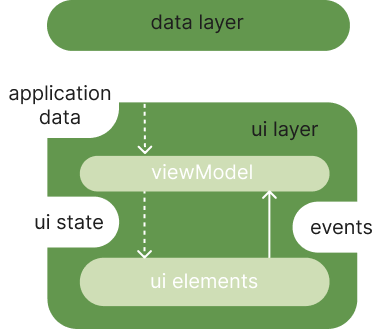
데이터의 state는 하위로 쭉 이동하며, 하위로부터 상위에게 event를 전달해 상위에서는 state를 변경해 이를 또 하위로 보내주게 된다. 결국 unidirection으로 state와 event가 이동하게 된다.
해당 말이 잘 이해가 가지 않는다면 아래 그림을 참고하자!
🔗 recomended architecture
그렇다면 원칙도 살펴봤겠다! 구글 권장 아키텍처는 어떠한 방식으로 구성해야 하는지 조금 더 깊게 살펴보자! 해당 방식은 권장되는 architecture이며 무조건적으로 따르기보다는 각 프로젝트에 따라 적절히 수정해 반영하라고 한다.
위 원칙들을 따르기 위해서는 필수적으로 Ui, Data 레이어가 필요하다!
그리고 클린아키텍처에서는 비즈니스 로직을 domain 레이어에 필수적으로 두게 하지만, layered architecture에서는 비즈니스 로직이 data 레이어에 들어 있을 수 있다. 따라서 ui 레이어에서 data 레이어에 직접적으로 의존이 가능하며, 필요하다면 domain 레이어를 둘 수 있다.
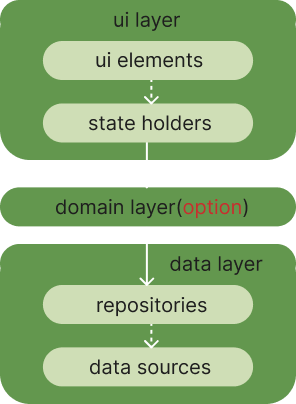
여기서 위 사진에서의 화살표는 의존성 방향을 나타낸다는 것을 명심하자!
layered architecture 의존성: ui -> (domain) -> data
🔗 권장 사용 기술
layered architecture를 구성하기 위해서는 다음 기술들을 사용되는 것이 권장된다.
- A reactive ad layered architecture
- UDF in all layers of the app
- a ui layer with state holders to manage to complexity of the ui
- coroutines and flows
- dependency injection best practices
🔗 각 레이어 살펴보기: UI layer
ui 레이어의 역할은 application data를 스크린에 보여주는 것이다. 위 이미지를 살펴본다면 UI 레이어는 크게 ui elements와 state holders로 구성이 된다.
여기서 ui elements는 말그대로 view혹은 compose가 된다. 이는 data를 화면에 rendering 하는 역할을 한다.
state holders는 viewModel과 같은 구성요소를 의미한다. 즉, ui 데이터를 홀드하고, ui에게 이를 노출하며, ui 관련 로직을 처리하는 역할을 한다.
🔗 각 레이어 살펴보기: data layer
data layer는 비즈니스 로직을 가지고 있으며, applicataion data를 ui layer에 노출하는 역할을 한다. data layer는 크게 repository와 dataSource로 구성된다. 여기서 다 복수로 표시되는 것에 주의하자! 즉, state hodler인 viewModel:repository는 1:다의 관계이며, repository:dataSource 역시 1:다의 관계이다.
여기서 repository가 뭐지 싶다면, repository pattern이라는 디자인 패턴을 한 번 공부해보자. 이는 여러 dataSource와 연결되며, ui에서 직접적으로 dataSource에 의존성을 갖지 않게 함으로써 ui layer에서는 ui 비즈니스 로직에만 집중할 수 있도록 한다. (ex: viewModel에서는 데이터가 로컬 db에서 오는지, 서버 api 응답으로 오는지 출처를 몰라도 된다!)
그리고 dataSource는 하나의 data source와 연관되어야 한다. 즉, 로컬과 서버를 함께 사용하게 된다면 로컬 dataSource, 서버 dataSource를 각각 구성해야 한다는 말이다. 이는 결국 application과 data system 사이 브릿지 역할을 한다.
🔗 각 레이어 살펴보기: domain layer
위에서 언급했듯이 layered architecture에서 domain layer는 option이다. 기존에 data layer에서 비즈니스 로직을 가지고 있어도 된다고 언급했었다. 하지만 data layer에 존재하는 비즈니스 로직이 재사용이 필요하다면? 이때 domain layer를 두는 것이다. 또는, 비즈니스 로직이 너무 복잡하다면 이를 domain 레이어에 별도로 빼서 관리할 수 있다.
다시 한 번 말하지만, 이는 option이다. 따라서 복잡한 비즈니스 로직이 없거나, 비즈니스로직의 재사용이 필요하지 않다면 ui layer -> data layer 구조만으로 충분하다!
🔗 각 layer 간의 의존성을 어떻게 관리해야 할까?
가장 쉬운 방법은 직접 필요한 객체를 생성해 사용하면 된다. 하지만 이렇게 될 경우, 각 컴포넌트간의 결합도가 강해진다. 결합도가 강해진다는 것은 추후 테스트를 진행할때 독립적인 테스트 작성이 어려워지게 된다.
따라서 이때 적용할 수 있는 방법으로 다음 두 가지를 제시한다.
DI- 직접 필요한 객체를 생성하지 않고, 런타임에 다른 클래스로부터 필요한 객체를 주입받는 방식이다.
Service locator- 이 또한, 의존성을 주입받는 방식이다. DI와의 차이점은 모든 의존성을
Service locator라는 하나의 객체에서 관리하게 된다.
- 이 또한, 의존성을 주입받는 방식이다. DI와의 차이점은 모든 의존성을
공식 문서에서는 Hilt를 활용한 DI 방식을 추천하고 있다.
🔗 클린 아키텍처와의 차이는 무엇일까?
그렇다면 이제 마지막으로 layered architecture와 클린 아키텍처 사이 차이점을 한 번 정리해보고자 한다.
가장 큰 차이점은 domain 레이어의 필수 여부, 의존성 방향이라 생각한다.
1. domain 레이어의 필수 여부
우선 layered architecture에서는 domain이 필수가 아니다. 따라서 비즈니스 로직을 data layer에 둘 수 있으며, ui layer에서 직접적으로 data layer에 의존할 수 있다.
하지만 clean architecture에서는 비즈니스 로직은 domain에 존재해야 한다. ui layer에서는 직접적으로 data layer에 의존하기보다는 domain에 의존하게 된다.
결국은 clean architecture가 layered architecture보다 더욱 강력한 layering 규칙을 가지고 있다고 할 수 있다. 그렇기 때문에 앱 규모가 커질 경우, 유지보수 측면에서 더 좋은 방식은 구현은 조금 복잡하더라도 레이어간의 책임과 역할이 더욱 명확히 구분된 clean architecture 방식이다.
2. 의존성 방향
- layered architecture
ui -> (domain) -> data
- clean architecture
ui -> domain <- data
의존성 방향을 보면 차이를 알 수 있겠는가? layered architecture에서는 domain의 역할이 단순히 ui -> data 사이에 존재해 복잡한 비즈니스 로직 혹은 재사용이 가능한 비즈니스 로직을 관리하는 역할을 한다.
하지만 clean architecture에서는 domain은 아무 의존성도 가지면 안된다. 추상도가 가장 높은 것이 domain 로직이고, 추상적이기 보다 구체 로직에 해당하는 ui, data 레이어는 domain 레이어에 의존하게 된다. 이렇게 됐을 때 domain 레이어는 여러 application에서 공유해 재사용할 수 있게 되는 것이다.
🔗 그렇다면 프로젝트에 어떤 아키텍처를 적용하는게 좋을까?
서비스의 복잡도 & 크기
필자가 생각했을 때 두 아키텍처 중 어떤 아키텍처를 적용할지는 서비스의 복잡도와 크기가 기준이 된다 생각한다.
만약 서비스가 정말 간단한 기능만을 제공하고, 비즈니스 로직 또한 복잡하지 않다면 layered architecture를 적용해도 문제가 없다.
실제로 필자가 작은 프로젝트에서 clean architecture를 적용했을 때 그 이점을 크게 느끼지 못했다. 그리고 관리해야 하는 파일이 더 많아 오히려 구조의 복잡도가 더 늘어난 것을 느낄 수 있었다.
만약 서비스 복잡도 및 크기가 충분히 크다면 clean architecture는 확실히 이점을 가져다 준다. 강한 layering 규칙이 있기 때문에 외부 변경으로부터 유연하게 대처가 가능하고, 하나의 변경사항을 반영하기 위해 많은 로직을 수정하는 번거로움이 줄어들게 된다.
그 외
필자가 진행하고자 하는 서비스는 규모도 작고, 복잡도도 높지 않다. 하지만 서버의 부재로 fireStore를 사용하고자 하는데, 클라이언트 개발자끼리 DB 구조를 결정하다보니 빈번하게 DB 구조의 변경이 일어나는 상황이 발생했다.
이럴 경우, layered architecture를 따른다면 DB 구조 변경이 일어날 때마다 ui layer의 코드 역시 계속해서 수정을 해줘야 한다. 따라서 필자는 중간에 domain 레이어를 둠으로써 data 레이어의 변경이 ui에 직접적인 영향을 주지 않는 방향이 더 나은 구조라 판단하였다.
이처럼 서비스 규모가 작더라도 본인들만의 기준이 있다면 그에 맞는 아키텍처를 판단해 적용하는 것이 맞다 생각한다!
댓글남기기