
[Android] 안드로이드에서 Clean Architecutre 적용 여정
🔗 들어가기 전
최근 프로젝트를 진행하며 clean architecture에 대해 학습하고, 직접 프로젝트에 적용해볼 수 있었다. 해당 게시글에서는 clean architecture의 개념과 이를 안드로이드에 어떻게 적용할 수 있는지에 대해 자세히 다뤄보고자 한다.
그리고 클린 아키텍처를 다루기 위해 꼭 필요한 DI에 대해서도 함께 다뤄보고자 한다.
클린 아키텍처는 책 [클린코드]의 저자 로버트 마틴이 제안한 시스템 아키텍처이다. The Clean Architecture 게시글을 보면 로버트 마틴이 기재한 clean architecture에 대한 내용을 확인할 수 있다. 필자는 해당 게시글을 읽으며 이해한 내용을 바탕으로 이번 게시글을 작성해보고자 한다.
🔗 the dependency rule
우선 clean architecture에서 가장 중요시 생각하는 dependency rule에 대해 살펴보자.
아래 사진 각 영역은 software의 서로 다른 영역을 나타낸다.
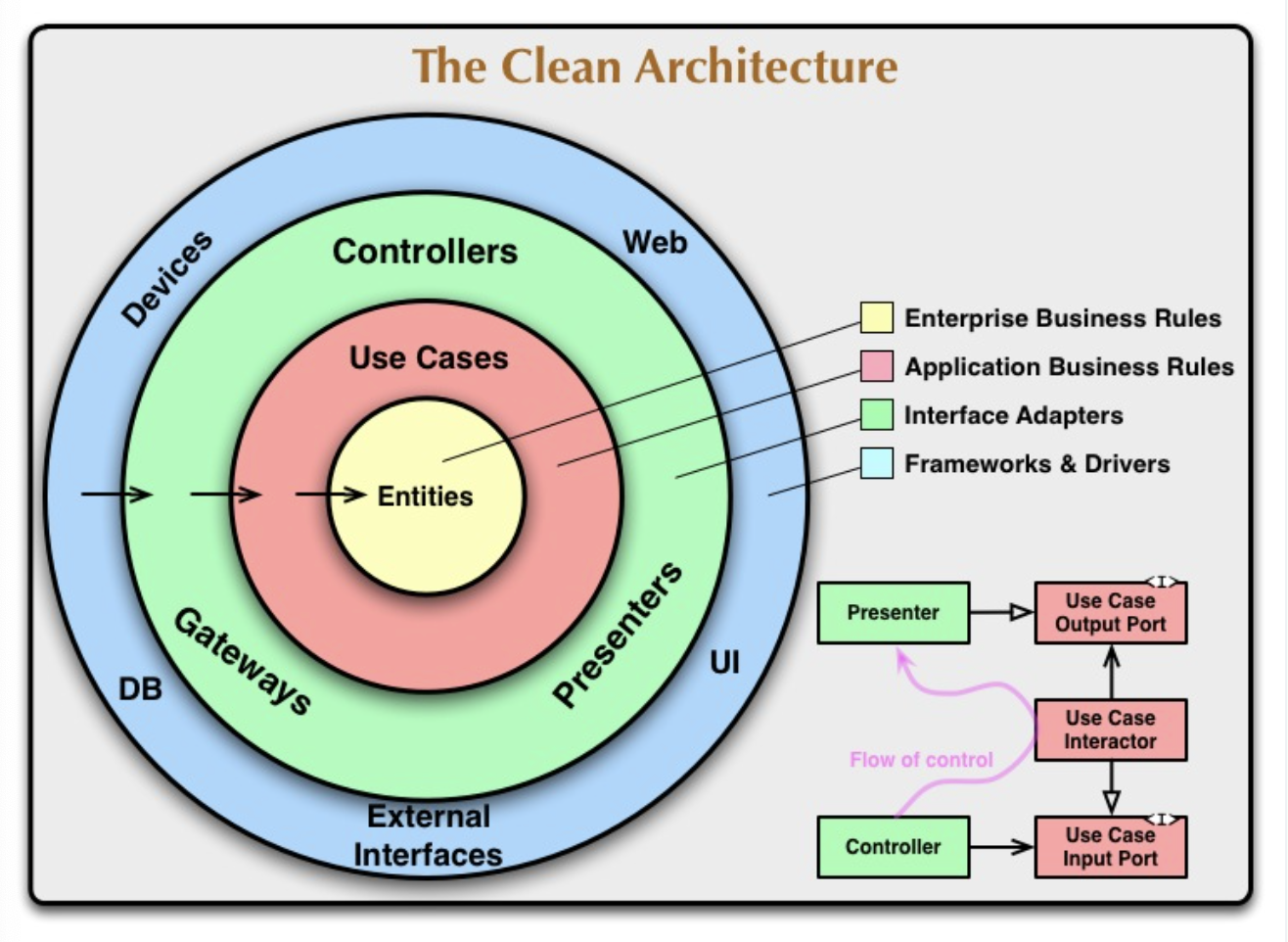
출처: https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
the outer circles are mechanism. the inner circles are policies.
우리는 해당 문장을 통해 다음을 이해할 수 있다.
- 안쪽으로 들어갈수록 높은 레벨의 영역을 의미한다.
- 즉, 안쪽으로 들어갈수록 더욱 추상화가 된다.
- 안쪽 영역은 policies이고, 그 밖의 영역은 policies를 활용해 mechanism을 정의하는 영역이다.
위 사진에서 설명하는 아키테처가 잘 작동할 수 있기 위해서는 dependency rule이 가장 중요하다.
source code dependencies can only point inwards.
사진 속 화살표를 통해 알 수 있듯이 의존성의 방향은 무조건 밖 -> 안을 향해야 한다.
즉, 안쪽 영역에서는 바깥쪽 영역을 몰라야 한다.
그렇다면 circle 안 각 요소가 무엇을 의미하는지를 알아볼 차례이다.
Entities
- 핵심 업무 규칙을 캡슐화한다.
- 만약 여러 플랫폼에서 서비스를 제공한다면 해당 영역은 모든 플랫폼에서 공유하는 영역이다.
- 가장 변하지 않으며 외부로부터 영향을 받지 않는 영역이다.
Usecase
- 위에서 설명한대로 여러 개의 플랫폼에 서비스를 지원한다면 특정 플랫폼에 특화된 업무 규칙을 포함한다.
- entity로 들어오고 나가는 데이터 흐름을 조작한다.
Interface Adapters
- 데이터 변환을 진행하는 adapter들이 존재한다.
- 외부에서 들어오는 데이터는 usecase / entity에 편한 format으로 변환되고, 내부에서 나가는 데이터는 database나 web 등의 외부 영역에 편한 format으로 변환된다.
frameworks and drivers
- framework나 database 같은 tool로 구성되는 영역이다.
- inner 영역과 연결시키는 코드 외에는 많은 코드를 작성하지 않는다.
🔗 crossing boundaries
여기까지 기본적인 clean architecture 개념에 대해 다루었다. 그렇다면 아래 사진을 통해 경계간 crossing하는 경우를 살펴보자!
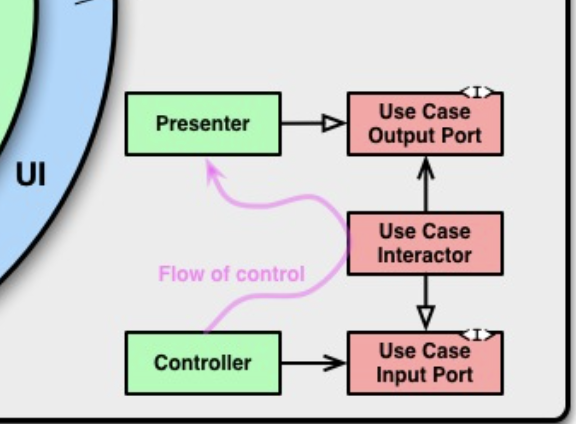
위 사진의 오른쪽 아래를 보면 제어의 흐름을 볼 수 있다. 여기서 우리가 주의깊게 봐야할 것은 usecase -> presenter로 가는 부분이다.
그렇다. 제어 흐름은 무조건 밖 -> 안을 향해야 하지만 경우에 따라 안 -> 밖이 필요할 때가 있다. 이때 우리에게 필요한 것이 바로 DIP(의존성 역전의 원칙)이다.
안드로이드에서는 DIP를 Hilt 통해 적용할 수 있다. 이 내용은 아래 부분에서 자세히 다뤄보자.
🔗 what data crosses the coundaries
그렇다면 경계 간에는 어떠한 데이터를 전달해야 할까?
isolated, simple, data structures are passed across the boundaries
즉, 단순하고 고립된 형태의 데이터 구조를 전달해야 한다. 만약 DB에서 전해주는 데이터 구조를 entitiy에서 그대로 사용한다면 고수준의 영역에서 저수준의 데이터 형식을 아는 것이기 때문에 위에서 말한 dependency rule이 위반되는 것이다.
그렇기 때문에 DB에서 전달하는 data 구조(DTO)와 직접 활용하는 데이터 구조(VO)를 별도로 두고 사용해 DTO가 변경되더라고 VO에는 영향을 주지 않도록 하는 것이다.
🔗 내가 생각하는 clean architecture의 핵심!
여기까지 왔다면 clean architecture의 상세 개념을 모두 학습한 것이다. 핵심 개념을 다시 한 번 짚고 실제 안드로이드에서는 이를 어떻게 적용할 수 있는지 살펴보자!
clean architectured의 핵심은 결국‘의존성은 저수준 -> 고수준으로 향하게 한다.’이다. 이러한 구조를 통해 entity를 유지하며 변경은 최소화하고 확장에는 유연한 구조가 설계되는 것이다.
🔗 android에서의 clean architecture
우리는 MVVM 패턴을 활용해 clean architecture를 적용할 수 있다.
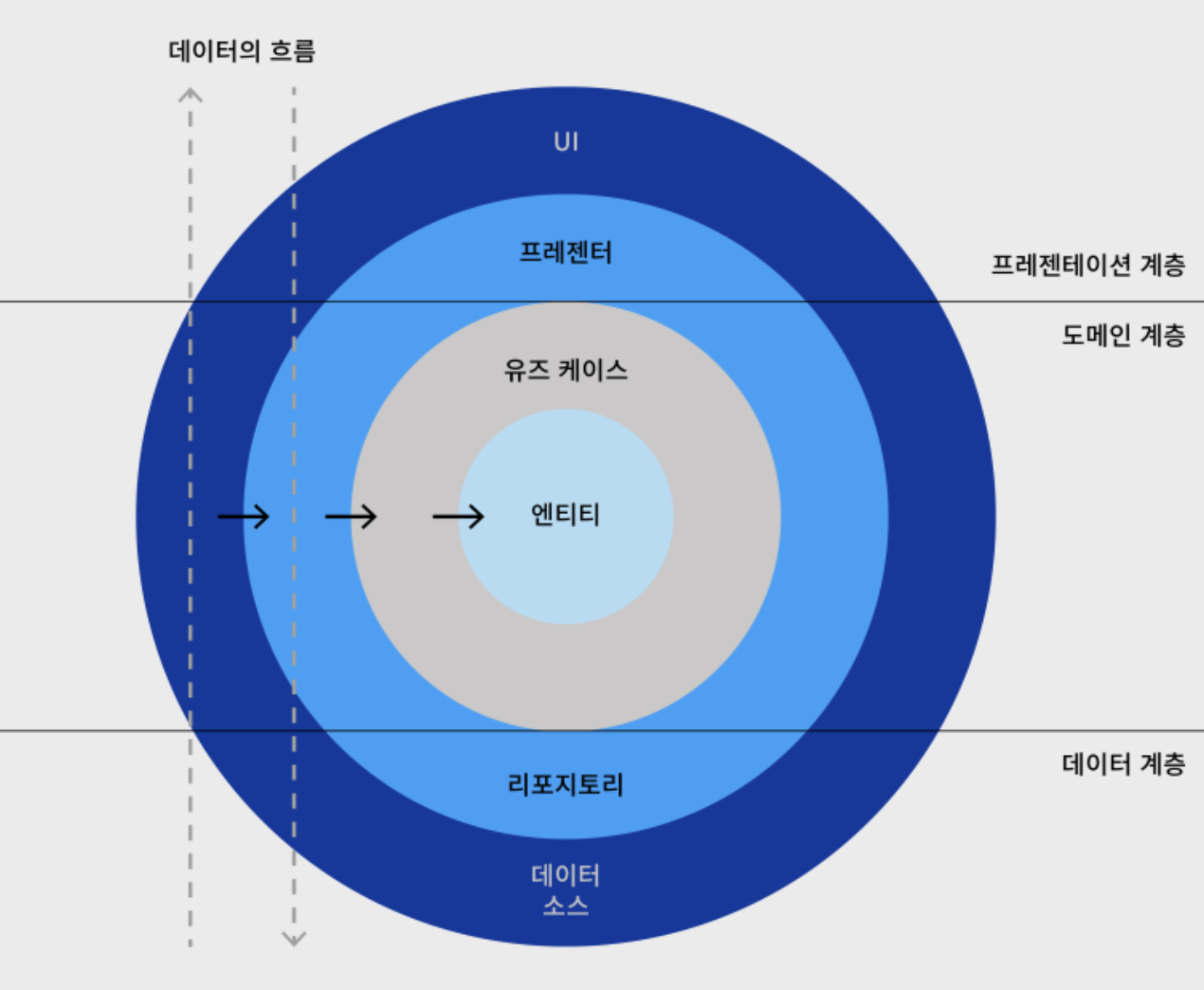
출처: https://meetup.nhncloud.com/posts/345
- presentation layer
view
- 플랫폼 의존적으로 구현
- 프레젠터 명령 수행, ui 화면 표시와 사용자 입력 담당
-
presenter - 사용자 입력에 대한 반응을 판단하는 영역
- like MVVM의 ViewModel
- domain layer
usecase: 비즈니스 로직 영역entity: 실질적인 데이터
- data layer
repository
- usecase가 필요로 하는 데이터의 저장 및 수정 등의 기능을 제공하는 영역
- DB, network 통신을 진행
-
data source: 실제 데이터의 입출력이 실행
데이터의 흐름에 따른 flow를 살펴보면 아래와 같다.
ui -> 프레젠터 -> 유즈케이스 -> 엔티티 -> 리포지토리 -> 데이터 소스
데이터 소스 -> 리포지토리 -> 엔티티 -> 유즈케이스 -> 프레젠터 -> ui
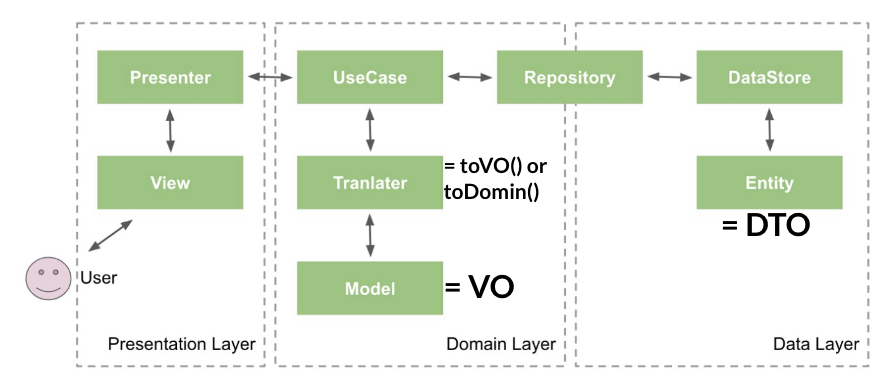
데이터 흐름을 조금 더 도식화한다면 위 사진과 같다. 여기서 우리가 짚고 넘어갈 부분이 있다.
1. clean architecture의 entity != data layer의 entity
- 위 사진에도 나와 있듯이 data layer의 entity는
DTO를 나타낸다. - domain의 model은
VO를 나타낸다. - 트랜스레이터는
DTO를VO로,VO를DTO로 변환시키는 작업을 진행한다.
2. domain 계층은 어떻게 data 계층에 데이터를 보낼 수 있을까?
바로 위에서도 언급한 DIP를 활용해서다.
원래라면 usecase에서 repository에 값을 전달하기 위해서는 domain이 data의 의존성을 가져야 하며, 이는 dependency rule의 위반이다!!

따라서 hilt를 활용해 의존성 주입을 해줌으로써 다음과 같이 dependency rule을 지킬 수 있게 된다.
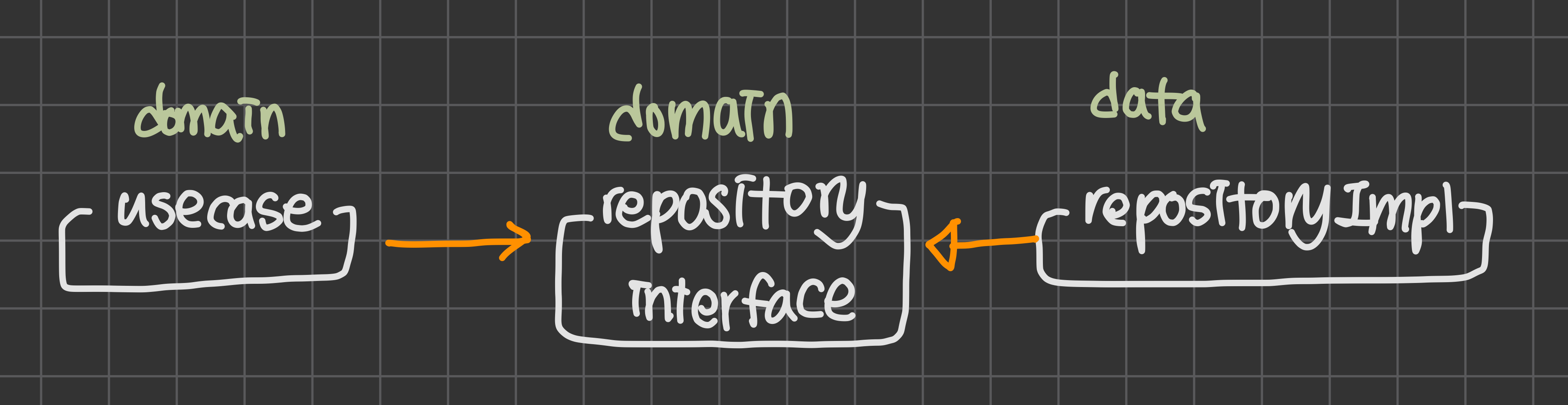
그렇다면 코드를 한 번 봐보자!!
// @Inject, hilt를 활용해 repository 의존성 주입!
class SuggestionUseCase @Inject constructor(
private val suggestionRepository: SuggestionRepository
) {
suspend fun getSuggestionList(): Result<List<SuggestionContent>> {
return try {
val response = suggestionRepository.getSuggestion().getOrNull()
?: return Result.failure(Exception("response is null"))
Result.success(createSuggestionContentList(response))
} catch (e: Exception) {
Result.failure(e)
}
}
...
}
실제 repositoryImpl는 data layer에 다음과 같이 존재한다.
class SuggestionRepositoryImpl @Inject constructor(
private val suggestionDataSource: SuggestionDataSource
): SuggestionRepository {
override suspend fun getSuggestion(): Result<MissionSuggestionVO> {
return try {
val response = suggestionDataSource.getSuggestion()
Result.success(response.data.toVO())
} catch (e: Exception) {
Log.e(TAG, "getSuggestion: ${this.javaClass} ${e.message}")
Result.failure(e)
}
}
...
}
그리고 repository를 활용해 구현체의 코드를 활용할 수 있도록 hilt를 통해 bind를 해준다.
@Binds
fun bindsSuggestionRepository(
suggestionRepositoryImpl: SuggestionRepositoryImpl
): SuggestionRepository
🔗 마무리
지금까지
- clean architecture란 무엇인지
- clean architecture의 핵심은 뭔지
- 안드로이드에서는 어떻게 이를 적용할 수 있는지
를 차근차근 알아 보았다.
내용은 길지만 핵심은 간단했다.
- 의존성 원칙을 따르자.
- 의존성의 방향은 저수준 -> 고수준이어야 한다.
- 결국 domain의 의존성을 줄이자.
- domain의 변경을 최소화해 확장에 유연한 구조를 만들자.

결과적으로 필자는 위 사진과 같이 프로젝트에 clean architecture를 도입할 수 있었다.
코드를 작성하며 의존성 원칙을 지키기 위해 많은 노력을 기울였다. 저수준 -> 고수준 의존성 방향을 고려하며 코드 작성을 진행했고, unidirection data flow를 고려하며 코드를 짜다보니 코드 작성에 깊이있게 고민하는 경우가 많았던 것 같다.
clean architecture를 도입하는 과정에서 domain의 중요성을 알 수 있었다. domain을 잘 설계하니 이를 중심으로 빠르게 개발을 진행할 수 있었다. 또한, 코드의 역할과 책임을 명확히 분리하니 작업을 진행할 때도 어느 부분에 코드를 작성해야 하는지 빠르게 파악할 수 있었다.
나아가 clean architecture와 많이 적용되는 multi module에 대해 학습하고 직접 적용해보았다. multi module에 대해서 관련된 내용을 게시글로 작성해보았다!!
댓글남기기